It’s non-trivial to compute a ranked list of best albums given the opinions of 31 different writers. We could go the lazy way and just have staff argue and editors decide what the AOTY is, but that’s unfair to everyone and is way too authoritarian. We could just have people pool votes, but that leads to way too many conflicts between albums with the same amount of votes (which editors need to resolve, which is unfair and upsets people), we could assign a particular value for each rank, have everyone rank their albums, and add up all the ranks. But that also has its own set of problems, and how do you set the values? As you can see, it’s non-trivial. Sure, you could just pick either of these schemes or anything else, but why do that when you can do something that is a lot more mathematically grounded? Since I’m essentially a statistician by trade (kind of), of course I’m going to try to do that. So here’s me explaining what I did, and sharing my code for anyone else interested in doing it the “””objectively correct””” way.
So, we need to establish a few principles for our algorithm. It needs to be fair to everyone. It needs to not depend on arbitrary hand-set parameters like “the value of a rank”. It needs to lead to as few conflicts as possible. It needs to make everyone as happy as possible. While the other principles are perhaps easy to establish, the key one is the last. How do we ensure an algorithm makes everyone as happy as possible? Obviously, there’s not really a mathematically optimal way to ensure that, but we can guide our algorithm in a way to achieve that as much as possible.
First, we asked each of our writers to submit a ranked list of their top 25 albums. We heavily encouraged that everyone submit exactly 25, because submitting less than that would upset the statistics and make it unfair towards their own preferences. Thankfully, we got that for the most part. We achieved this via a google doc where everyone was assigned a column, and each album was assigned a row (people were free to add their rows to the sheet if an album they want to enter isn’t in the list). Then, I collected that data, exported it to a CSV, and wrote a Python script to read and process it. That’s the easy part (actually, that was quite frustrating to arrange and get everyone to participate), now we can move onto the algorithm.
The algorithm I used last year worked pretty well, so I decided to reuse it with a few tweaks. To reiterate, it’s what I call pairwise comparison. The idea is to look at how each person ranked a particular album in their list compared to another particular album. So, let’s assume my top 5 (for the sake of simplicity) would be albums: A, B, C, D, E in order. And we have Eden, whose top 5 is albums D, C, A, F, G in order. Finally, Nick has G, F, H, I, A. I ranked A over 4 albums, so A gets 4 points from me. Eden ranked A over 2 albums, so it gets 2 points from him. Nick ranked it over 0 albums, so it gets 0 points from him. The final score for A from our group would be 6. If we look at C, the score would be 2 + 3 + 0 = 5. G would have 0 + 0 + 4 = 4. In fact, if we do the math for all these albums, the final scores would be: A: 6, B: 3, C: 5, D: 5, E: 0, F: 4, G: 4, H: 2, I: 1. So the ranked list would be: A, C/D, F/G, B, H, I, E. When we add more people and longer lists and more albums to this equation, it’s basically impossible to get conflicting scores, so it’s pretty easy to resolve. In the end, the albums the most people scored highest would be scored highly, but people’s individual AOTYs would also be scored decently high as long as a few other people voted for them as well. There’s a little bit more to the math, but that’s generally how it works.
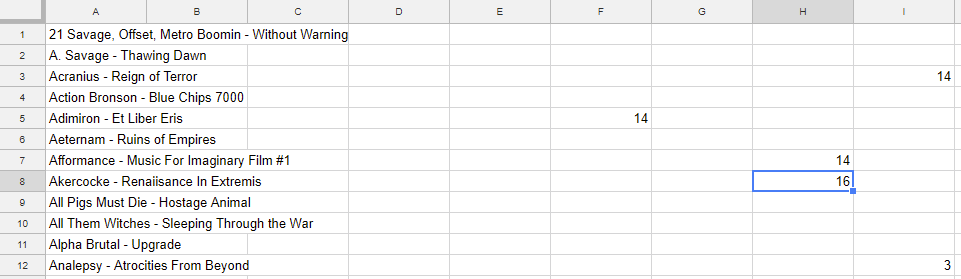
Now we get to my code. Note: code is provided as-is, and it works specifically with the way I’ve formatted the data. If you want to change it for your own purposes, feel free. I haven’t had a chance to comment the code, but it’s fairly straightforward except for a few dodgy variable names. It assumes the CSV file is formatted as such: Each row corresponds to an album. The first column in the row will be the album title. Every other column is a person’s ranking. If a person has ranked an album, the cell will contain a numeric value between 1 and 25 (1 being AOTY). For example, here the person who corresponds to column H ranked Akercocke as their #16.
Collecting that CSV is up to you, but then you can just feed it to the code below. In the end, it will produce something like:
124: (16) Akercocke – Renaiisance In Extremis, voted for 2 times with mean score: 17
for each album, where the leftmost value is the rank, the parenthesized value is the score it received, and the rest of the information is self-explanatory. If you run a big site with several members, feel free to use this code to arrive at the objective AOTY list for your site! We’ve done it for a second time in a row now and the staff has been happier with the lists these pasts years than ever. Previous methods always resulted in some people feeling shunted, but this makes everyone as happy as possible. So, without further ado, here’s the code:
[code language=”python”]
import csv
from collections import defaultdict
albums = []
scores = {}
data = []
with open(‘final.csv’,’r’) as f:
reader = csv.reader(f)
for row in reader:
albums.append(row[0])
scores[row[0]] = 0
data.append(row)
comps = []
for i in range(len(data)):
comps.append([0]*len(data))
t_data = map(list, zip(*data))
num_people = len(t_data)
mentions = defaultdict(int)
votes = defaultdict(list)
for i, person in enumerate(t_data):
if i == 0:
continue
for j,album in enumerate(person):
if album:
mentions[albums[j]]+=1
votes[albums[j]].append(int(album))
for k,album2 in enumerate(person):
if album2:
if int(album) < int(album2): comps[j][k] += 1 results = [] for i,album in enumerate(comps): result = 0 for other in album: result += other results.append(result) title = albums[i] scores[title] = result scores2 = [[v,k] for k,v in scores.items()] results = sorted(scores2)[::-1] means = {} for item in mentions: means[item] = sum(votes[item])/(mentions[item] if mentions[item] > 0 else 1)
for i,result in enumerate(results):
title = result[1]
value = result[0]
try:
print str(i+1) + ": (" + str(value) + ") " + title + ‘, voted for ‘ + str(mentions[title]) + " times with mean score: " + str(means[title])
except:
pass
[/code]